That distinction — between the brain and the nervous system — is the most consequential thing AppWorks has learned across more than a decade of building mobile tools for media and sports organisations.
For media organisations, the right AI assistant architecture combines retrieval-augmented generation, model routing and data governance so the system fits the newsroom, not the other way around.
Most AI pitches focus on the wrong thing entirely.
For newsrooms publishing multiple times daily, that gap matters a lot - and this retrieval problem is the same one that undermines most archive-based workflows.
The Framework: Brain vs. Nervous System
Vendor conversations almost always start the same way. Which model powers it? Is it GPT-4? Is it the latest release? The implication is that a bigger, more capable model produces a more useful product - that the brain is the differentiator.
This is what transforms the assistant from a generic tool that is competent everywhere into a domain-specific tool that is reliable in your newsroom or club.
It isn't.
The nervous system is what actually determines whether an assistant is useful in your specific organisation. The gateway, the data pipeline, the routing logic and the governance layer bridge the gap between a model trained on the open internet and a tool that knows your editorial style guide, your ten-year archive of match reports and the morphological rules of a regional language that most frontier models handle poorly.
A model cannot know what it was never shown. Architectural decisions are what fill that gap.
This reframe changes the evaluation question entirely. Not "which model do they use?" but "how does their architecture govern, route, and ground the model they use?" Those are structurally different questions, and they produce structurally different outcomes. According to OpenText Blogs, only 12% of organisations claim their data is actually AI-ready - which means the vast majority of AI deployments are running a capable brain through a nervous system that was never properly built.
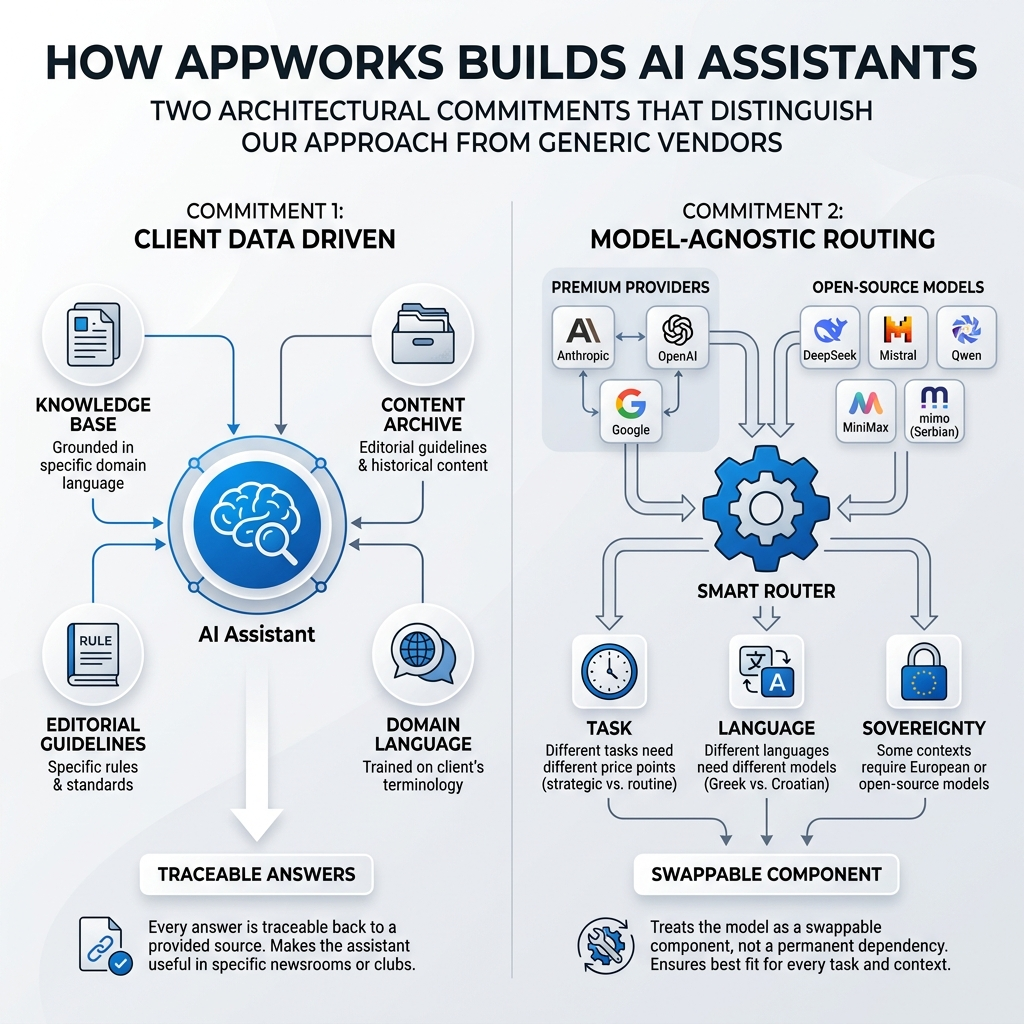
Commitment One: Your Data Drives Every Answer
Consider what happens when an AI assistant fabricates a match result. Or misquotes an editorial policy that was updated six months ago. Or confidently answers a question about a player transfer using information from a training dataset that predates the deal. The assistant doesn't just underperform. It actively erodes the editorial credibility your organisation spent years building.
The practical implication is straightforward: when a better model emerges for your language or your task type, you adopt it. No vendor renegotiation. No application rewrite. Just a routing update.
AppWorks addresses this through Retrieval-Augmented Generation - RAG - which ensures every response the assistant produces is derived from content the client has explicitly provided: articles, archived footage transcripts, editorial guidelines, club records. Every answer is traceable back to a client-provided source. That traceability is what makes the assistant editorially accountable rather than generically plausible. And client needs to be able to add or change that data easily - through 2 or 3 clicks, in easy to use admin interface.
If you are building or evaluating an AI assistant for your organisation and want to understand how this architecture applies to your specific content, language, and budget constraints - we are happy to walk through it without a sales deck. Get in touch with the AppWorks team.
This matters more than it sounds.
The system includes conservative correction prompts that instruct the model to prefer "I don't know" over fabrication when retrieved context is insufficient. That's a structural safeguard, not a statistical hope.
No architecture eliminates error entirely. But this one makes error traceable and correctable, which is a fundamentally different failure mode from a system that confabulates with confidence.
Automated pipelines re-index new articles, transcribed broadcasts and updated guidelines continuously. So the assistant's knowledge base reflects today's content, not last year's training data.
We have also built a place where your "chatbot librarian" can check answers where the assistant was not confident enough to answer — or has refused to answer. With this approach, you can see what is missing and decide how to train it further.
For newsrooms publishing multiple times daily, that gap matters a lot. It is the same retrieval problem that undermines most archive-based workflows.
This is what transforms the assistant from a generic tool that is competent everywhere into a domain-specific tool that is reliable in your newsroom or club.
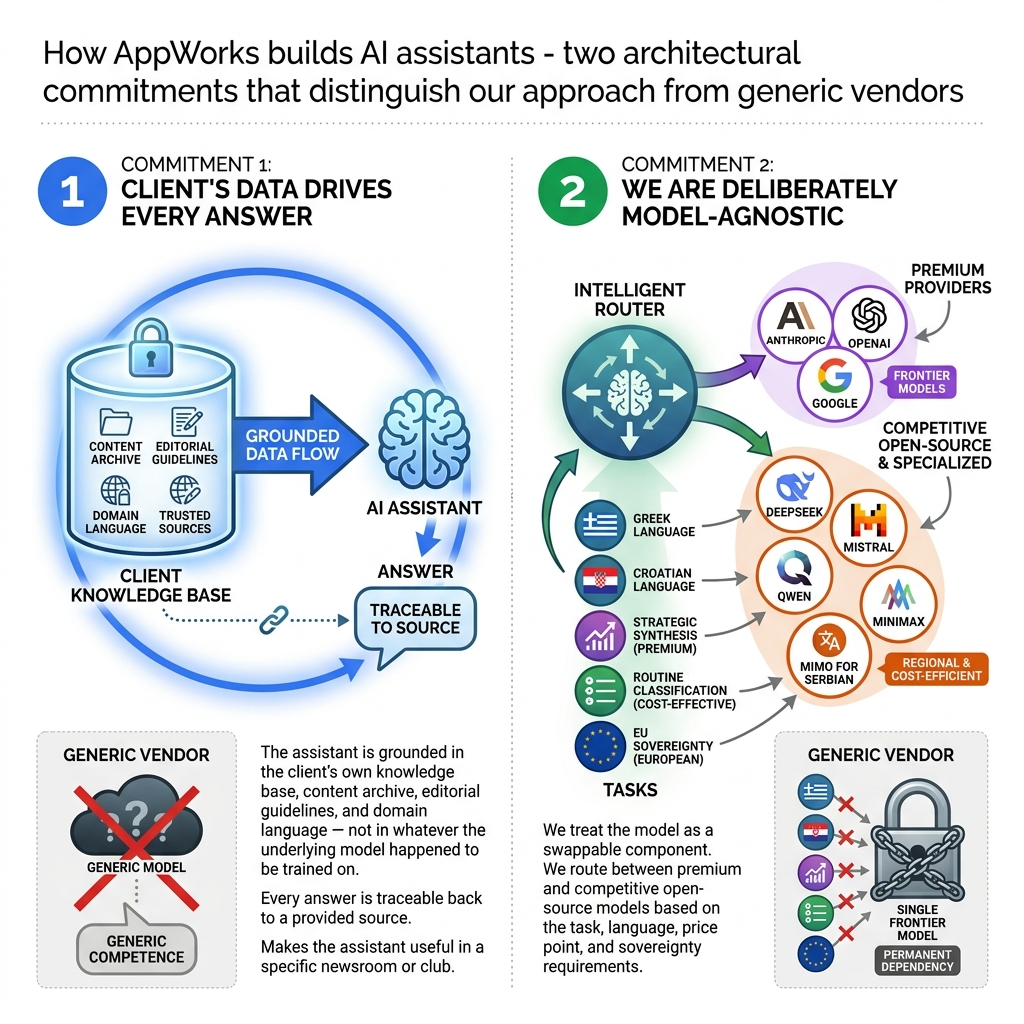
Commitment Two: The Model Is a Swappable Component
AppWorks operates a self-hosted LLM gateway and model-agnostic AI gateway, a routing layer that allows the underlying model to be changed per task, per language and per client without touching application code.
The model is a component that can be replaced quickly. The architecture stays stable.
Task routing is deliberate and specific. Tasks can be routed to Claude, GPT or Gemini, or to open models like Mistral or mimo-v2-pro, because some models may handle SEO logic better at a lower price than larger frontier models.
English routine classification work is routed to cost-efficient models like DeepSeek-chat. Not because they are better than the big three, but because they can do the same job and save you money on tokens.
Strategic synthesis tasks can justify a premium provider when the output warrants it — but only then. The gateway tracks exactly what each task costs per client.
Language is not a minor variable. What performs well for Greek does not perform well for Croatian.
What handles English idiom fluently can stumble on the inflectional complexity of South Slavic languages in ways that produce subtly wrong outputs — outputs that look correct to anyone who isn't a native speaker, which is precisely the failure mode that's hardest to catch.
A model-agnostic AI gateway is the only AI assistant architecture for media organisations that allows you to act on that reality rather than accept a one-size-fits-all compromise.
For EU-funded and public-sector clients, there's an additional dimension. Data sovereignty requirements often make European or open-source models non-negotiable.
A gateway architecture makes compliance a routing decision rather than an infrastructure rebuild. When the requirement changes — and in the current EU regulatory environment, it will change — you adjust a routing rule, not a contract.
The practical implication is straightforward: when a better model emerges for your language or your task type, you adopt it.
No vendor renegotiation. No application rewrite. Just a routing update that reduces AI vendor lock-in.
Why This Architecture Matters for Sceptical Decision-Makers
Technical decision-makers at media and sports organisations are being asked to commit to AI infrastructure while simultaneously being burned by hallucinations, generic answers and AI vendor lock-in from solutions that prioritised model prestige over architectural soundness.
The scepticism is earned.
But the objections have structural answers.
The hallucination objection: RAG constrains the answer space to verified client content, and conservative prompting instructs the model to acknowledge ignorance rather than invent. Error becomes traceable. That's categorically different from hoping a large model happens to be accurate.
The vendor lock-in objection: the gateway layer means clients own the architecture, not a dependency on any single provider's pricing or availability decisions. If a provider changes its pricing model — and they do — you have options.
The cost sustainability objection is addressed by routing. Premium frontier models are reserved for tasks where their capability is genuinely necessary. Routine tasks run on models that cost a fraction of that, with the gateway tracking exactly what each task costs per client.
Per-client cost attribution is built into the layer, making AI spending visible rather than a black-box line item on a vendor invoice. In our experience, visible cost control is the difference between a pilot that scales and one that gets cancelled after the first quarterly review.
And the regional language objection is addressed by specialisation. The same underlying platform that serves an Italian basketball club routes to mimo-v2-pro. The same platform serving a Slovenian media portal routes to a model optimised for Slovenian.
What to Ask Any AI Vendor Before You Commit
Three questions.
- Can you show me which source document this answer came from? If the answer is no, you are buying a confident-sounding system with no editorial accountability. That's a liability, not a tool.
- What happens when a better model is released - new contract, new integration or new application? If the answer involves any of those, you are buying a dependency. The model will improve. Your architecture should be able to absorb that improvement without friction.
- How does your system handle my specific language? Not English. The inflected, regionally specific language your audience reads and your journalists write in. If the answer is vague or involves a demo in English, the system will be generic when it matters most.
AppWorks has been building mobile app platforms for media and sports organisations since 2013. The architectural commitments described here are not a pitch. They are the conclusions reached after a decade of production deployments across diverse clients, languages and content types — the same reasoning that shaped tools like LitteraWorks and Pchela.
If you choose an AI vendor based on which model they use today, you are making a permanent infrastructure decision based on a temporary capability snapshot. You are locking yourself into costs, dependencies and failure modes you won't discover until they damage your brand.
The right question is not which model the vendor uses today. It's whether their architecture gives you control over which model you use tomorrow.
If you are building or evaluating an AI assistant for your organisation and want to understand how this architecture applies to your specific content, language and budget constraints, we are happy to walk through it without a sales deck. Get in touch with the AppWorks team.