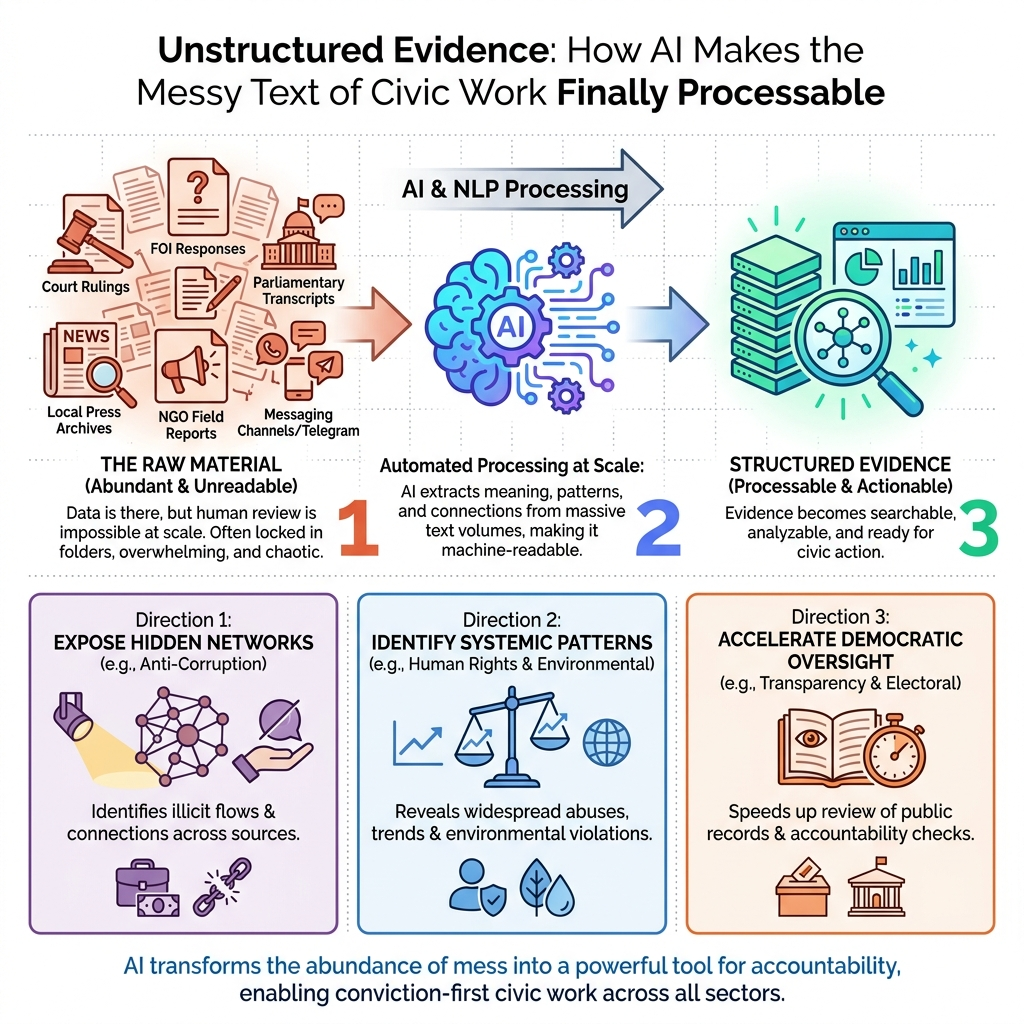
Somewhere in a folder — or, more likely, in several hundred folders — sits the raw material of democratic oversight. This unstructured evidence includes court rulings, parliamentary transcripts, FOI responses, local press archives, NGO field reports, and the sprawling record of public life captured in messaging channels that no human team can read at scale.
The evidence is there, whether it lives in a Google Drive, on a secure server, or in JSON files prepared for processing. What has changed is that civic organizations can now process it with AI, and the infrastructure for unstructured evidence and civic accountability is no longer limited to the best-funded institutions.
Every unread FOI response is accountability deferred. In fast-moving political environments, deferred accountability is accountability abandoned.
The Archive Was Never the Problem
Consider what unstructured evidence actually looks like on a Monday morning. It is a scanned PDF from a regional ministry, formatted differently than the one from last quarter. It is a parliamentary session transcript in a Slavic language variant that generic transcription tools consistently misread.
It is also twelve Telegram channels that someone on the team monitors manually, flagging posts in a shared spreadsheet that grows faster than anyone can read it.
Civic organizations are not evidence-poor. They are processing-poor.
The bottleneck has been the human inability to process proof’s volume before the political cycle moves on. A story that requires three months of manual document review to surface is often a story that arrives after the vote has passed, the official has resigned, or the narrative has been captured by someone else.
And the volume is accelerating. According to research from Komprise, the amount of data that enterprises now store has increased 57% over the previous year. The archive grows, the team does not, and the gap between what exists and what gets read widens every quarter.
This is the structural problem. Manual workflows cannot close it. They can manage it, partially, for a while.
How Civic Organizations Process Unstructured Evidence with AI
Most conversations about AI in civic or media organizations default immediately to content generation: writing summaries, drafting reports, producing first-pass translations. That is a legitimate use case, but it is not the highest-value one.
The more consequential application is evidence ingestion.
An AI pipeline designed for unstructured evidence in civic accountability work does something different from a chatbot. It ingests inconsistent formats — scanned PDFs, audio recordings, JSON files with different structures, HTML-scraped press content, exported Telegram logs — and normalizes them into a comparable structure.
It applies entity recognition to surface the names, institutions, and legal references that connect documents to each other. It makes a multi-year archive searchable in ways that a keyword search in a spreadsheet never could, because it understands context, not just character strings.
Think of it this way: the AI model, whether that is OpenAI, Claude, or a fine-tuned open-source variant, is only one part of the system. What determines whether it works for a specific civic organization is the architecture around it — how data is routed, how the model is grounded in the organization’s archive and editorial rules, and how it handles regional language morphology that generic tools get systematically wrong.
South Slavic languages are a clear example. The morphological complexity — case endings, verb aspects, the way proper nouns decline — creates accuracy problems that majority-language-trained tools handle poorly.
The signal that this has shifted from experimental to baseline: according to industry research, 97% of publishers now consider back-end automation - transcription, copyediting, content tagging - either "important" or "essential." The frontier question is not whether to build this infrastructure. It is how to build it correctly for the specific evidence your organization holds.
The Cost Collapse That Changed the Calculation
Two years ago, running large-scale textual analysis across a multi-year archive required either a substantial technical budget or a partnership with a university research team. AI inference costs dropped approximately 100x in two years. That is a category shift.
What was previously a technology problem is now an architecture problem. The question is no longer "Can we afford to process this archive?" It is "Have we built the right pipeline to make our archive usable?" Those are different problems with different solutions.
The models are capable enough. The gap is in the infrastructure that makes an organization's existing archive legible to those models. Messy formatting, inconsistent naming conventions, mixed languages, scanned documents without text layers: these are not obstacles to wait out. They are the actual working conditions, and the right pipeline is designed to operate within them, not around them.
This connects directly to democratic access. According to Granicus, digital intake in government increased by nearly 30% in a single year, driving demand for AI infrastructure that can keep pace. The organizations monitoring public institutions need the tools to match that acceleration.
The archive your organization has accumulated over years - inconsistent, multilingual, partially scanned, imperfectly formatted - is not a liability to clean up before AI can help. It is the most valuable input you own. The right nervous system is built to work with it as it is.
The Specific Risks That Make This Work Different
The answer is not to avoid AI - the answer is to architect it correctly.
Grounding models in an organization's specific, verified archive - rather than allowing them to generate freely from general training data - is the design principle that separates reliable civic AI from experimental civic AI. Retrieval-augmented generation, where the model is required to cite specific source documents rather than synthesize from general knowledge, is the minimum viable standard for accountability applications.
The language accuracy problem sits in the same category. A tool trained predominantly on English-language data will misread the parliamentary vocabulary, the proper nouns, and the regional press conventions that matter most in local accountability work. This is a systematic accuracy problem that compounds across thousands of documents.
The broader institutional context reinforces why architectural discipline matters. Federal AI use cases in the USA increased 105% between 2024 and 2025, reaching 3,611 individual cases (Nextgov/FCW) - growth that has outpaced the governance frameworks around it. For civic organizations building these pipelines, that makes grounding, verification, and source attribution more important, not less.
So yes, build the pipeline. But build it with retrieval at the center, not generation.
Three Directions This Infrastructure Opens Up
These are categories of work that become available when the infrastructure is in place - the analytical moves that were previously cost-prohibitive or simply impossible at the scale that matters.
Parliamentary transcript analysis at scale. When every session is transcribed, normalized, and made searchable against a longitudinal archive, patterns become visible across years rather than weeks. Shifts in rhetorical framing around a specific policy area. Voting behaviour that correlates with donor disclosures. Procedural manoeuvring that only becomes legible when you can see it across fifty sessions rather than five. Organizations like CRTA, which monitors parliamentary processes for civic accountability purposes, represent exactly the kind of work that benefits from this infrastructure: analysis that previously required a researcher to manually read thousands of pages becomes a standing query rather than a project.
FOI response processing and cross-document comparison. FOI responses arrive in inconsistent formats, often as scanned PDFs with no text layer, formatted according to whatever convention the issuing institution happened to use. Comparing them across institutions or across time periods is effectively impossible at scale without a normalization pipeline. With one, the contradictions and omissions that are the substance of accountability work become findable rather than accidental. The discrepancy between what Institution A reported in 2022 and what Institution B reported in 2024 does not require a researcher to hold both documents in memory simultaneously. The pipeline surfaces it.
Multi-channel signal monitoring across languages. Local press, regional social channels, and messaging platforms carry accountability signals that never reach national media. Monitoring them continuously, in the languages they are actually written in, and connecting local event patterns to national narratives is work that a three-person team cannot do manually. But it is work an AI pipeline can do across the full archive, flagging the signal clusters that warrant human attention.
None of this requires inventing new evidence. It requires building the infrastructure to finally read what already exists - which is the argument this entire piece has been making about unstructured evidence civic accountability AI work depends on.
Building the Nervous System, Not Just Running the Brain
The organizations that will do the most consequential accountability work over the next five years will not necessarily be the ones with the largest teams. They will be the ones that built the right infrastructure around the evidence they already have.
If your organization is sitting on an archive of unprocessed transcripts, FOI responses, or monitoring data and wondering whether the infrastructure to make it legible is within reach - that is exactly the conversation worth having. AppWorks works with teams across 50+ organizations on four continents to figure out what is actually buildable, in your languages, with your data, for your workflow. Start that conversation.