This is not a hypothetical. It is a pattern playing out across newsrooms, broadcasters, and sports organizations every single day. According to Pixitmedia, 85% of media leaders plan to migrate to a unified media archiving platform by 2027 — which suggests the majority have already accepted that what they currently have is not working.
The problem is not awareness. It is understanding exactly what a broken media archive management system actually costs.
How Archives Become Black Holes
Archives do not collapse overnight. They degrade incrementally, file by file, as photographers upload assets under generic camera-generated names and move on to the next assignment.
Manual folder structures create an illusion of organization that works at small volume. The moment archive size outpaces the team's capacity to maintain it consistently, that illusion cracks. What looked like a filing system reveals itself as a graveyard of best intentions.
There is also the tribal knowledge problem. One or two long-tenured employees effectively become the human search engine for the entire archive. But that knowledge walks out the door during a sick day, a resignation, or a restructure. There is no backup.
According to IDC via Forbes, 80% of enterprise data is unstructured, and 90% of that unstructured data is never analyzed. In media, that translates directly to unfindable footage, unpublishable photography, and archive budgets that generate zero editorial return.

The Stock Photo Paradox
A sports broadcaster's editor. Thirty minutes before airtime. Searching through thousands of generically named files before abandoning the search entirely and reaching for a stock photo — for a match their own camera crew filmed last season.
That is the Stock Photo Paradox. The direct licensing cost is the visible part. But there is a second cost that never appears on an invoice: the editorial time spent searching, failing, and ultimately settling for a suboptimal asset under deadline pressure. That time is gone regardless of what the license fee looks like.
Proprietary imagery carries value that stock photos structurally cannot replicate — exclusive access, authentic moments, visual identity built over years of coverage. The moment that content becomes unfindable, that value disappears from the organization's operational reality.
Why Manual Tagging Always Fails at Scale
Manual metadata entry is not a workflow. It is a debt repayment plan with no end date.
For every hour a team spends tagging legacy assets, new untagged assets are being ingested. The backlog does not shrink. Consistency collapses across large teams — one editor tags by location, another by subject name, a third by event type. The result is a metadata schema that is technically present but practically useless for cross-archive search.
Manual tagging projects also get deprioritized under deadline pressure. The archive is least useful precisely when it is most needed. Metadata creation needs to happen at the moment of ingest, automatically, before the asset ever enters the archive.
The Compliance Risk Hiding in Your Archive
An unmanaged archive is not just an editorial inconvenience.
GDPR introduces specific obligations around identifiable individuals in imagery. An archive with no face-level metadata makes it close to impossible to respond to a data subject access or deletion request with any confidence. You cannot delete what you cannot find. And "we cannot find it" is not a defensible compliance position.
Broadcasters and sports organizations operating under EU jurisdiction face particular exposure. The volume of identifiable individuals in event photography is exceptionally high — athletes, officials, spectators, minors at youth events. Without metadata linking those identities to specific assets, the compliance surface area is enormous.
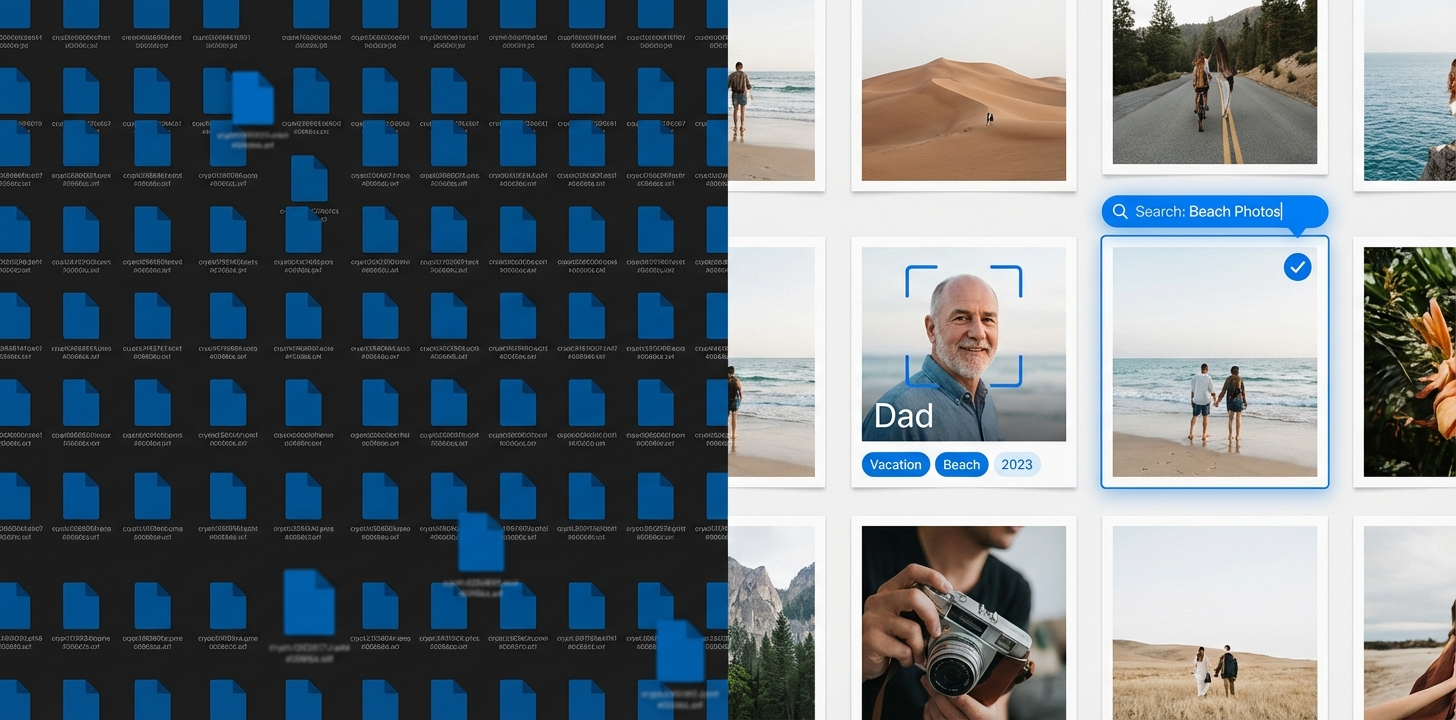
What an AI-Powered Archive Actually Looks Like
The fundamental shift that AI-powered media asset management enables is moving metadata creation from a manual, post-hoc activity to an automatic process that happens at ingest — before the asset enters the archive, before anyone has to remember to tag it.
Pčela, AppWorks' Cloud DAM platform, is built specifically around this editorial use case. AI face recognition identifies individuals automatically, so the archive becomes searchable by person, not just by filename or upload date. Auto-tagging for objects, scenes, and events extends this further — assets uploaded years ago under generic filenames become searchable by contextual content, restoring archive value retroactively.
On GDPR compliance: Pčela is EU-hosted on Hetzner servers and fully GDPR compliant. Face-level metadata means you can locate, audit, and act on assets containing specific identifiable individuals — exactly what a data subject deletion request requires.
Pčela's integration with mPanel CMS eliminates the archive-as-silo problem. The archive surfaces directly within the content creation environment. Editors search, find, and publish without leaving the workflow they are already in. This is not a minor convenience — it is the specific mechanism that determines whether the archive gets used or ignored at the moment it matters most.
Industry research from MediaValet shows 83% of organizations now report their DAM as their primary video storage system, up from 68% in 2025. The direction is clear. But storage is not the core problem most organizations need to solve. Findability is.
The Archive Problem Has a Solved Answer
The AI that powers face recognition and auto-tagging in media asset management is mature, deployed, and producing results across real editorial workflows.
Pčela is trusted by 50+ organizations across four continents — a workflow-ready solution with the deployment breadth to demonstrate that the approach works at scale, across different market contexts, regulatory environments, and archive sizes.
Organizations still running on folder hierarchies and tribal knowledge are paying a daily tax: in stock photo licenses, in editorial time, in compliance exposure, and in a media archive management problem that grows harder to solve with every passing month.
The architecture for fixing it exists. The question is how long to keep paying the alternative.
If your team has ever used a stock photo for an event you covered, your archive has a findability problem. See how Pčela makes your entire media library searchable in seconds — book a demo and find out what your archive could actually look like.